前回の記事で OneDrive for Business (以下 ODfB )や SharePoint で、つまり Microsoft 365 で PDFファイルを開くと利用できるPDFファイルビューアーに、ここ半年で結構機能が追加されたと書きました。
この記事では長くなってしまうので半年前のスクショと比較して増えた機能を紹介するところまででしたけど、やはり実際に触ってみたところを備忘録として残しておきたいので、今日はその中から「抽出」機能を試してみます。
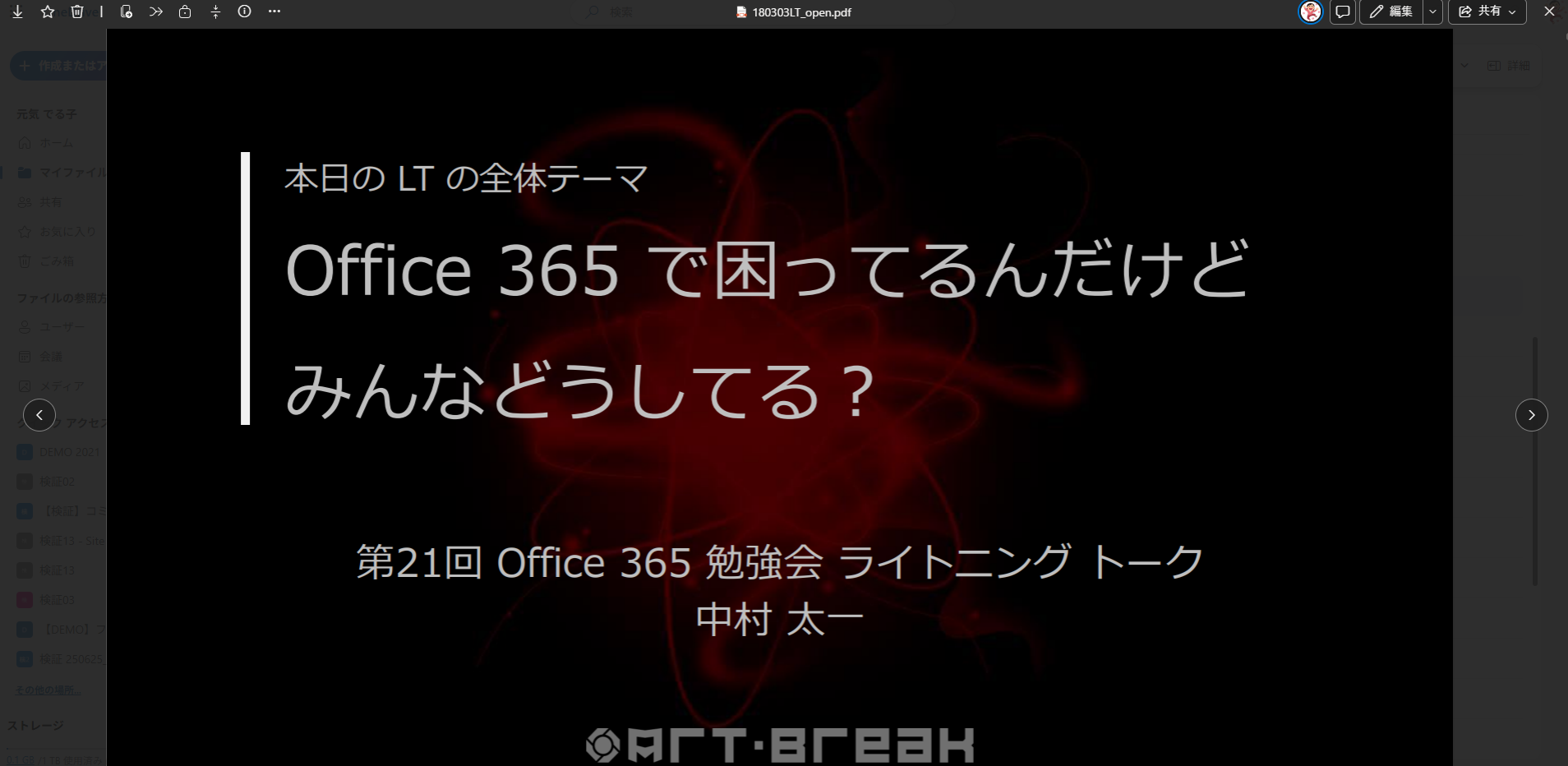
▼ ODfB からPDFファイルを開く
このPDFファイルは人生で初めてIT技術コミュニティイベントで登壇した時に使ったスライドをPDF化したものです。たしか2018年なので7~8年前です。まだ Microsoft 365 じゃなくて Office 365 と呼ばれていた時代。ここで僕は「 Microsoft Teams の Teams って チームス なの? チームズ なの?」と提起をしたライトニングトークでした。懐かしいです。それは置いといて…、
▼抽出ボタンをクリックすると、
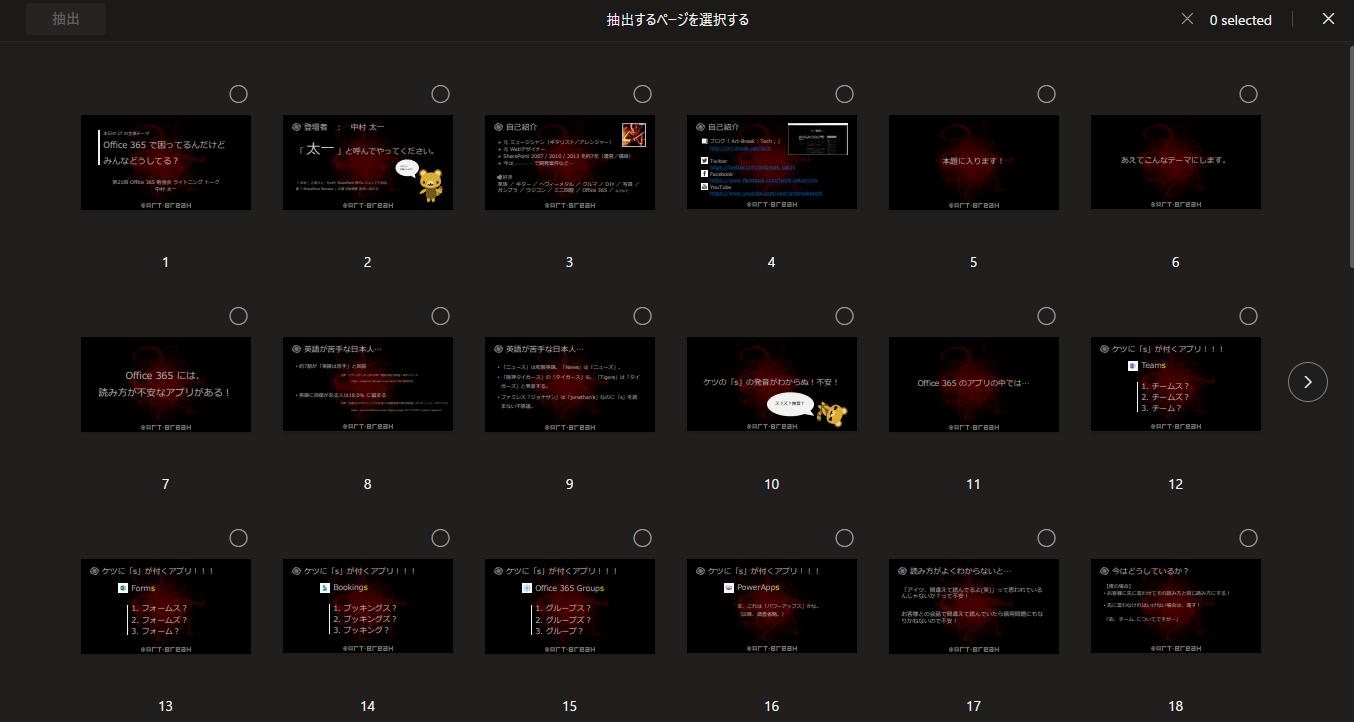
▼ページ一覧が表示される
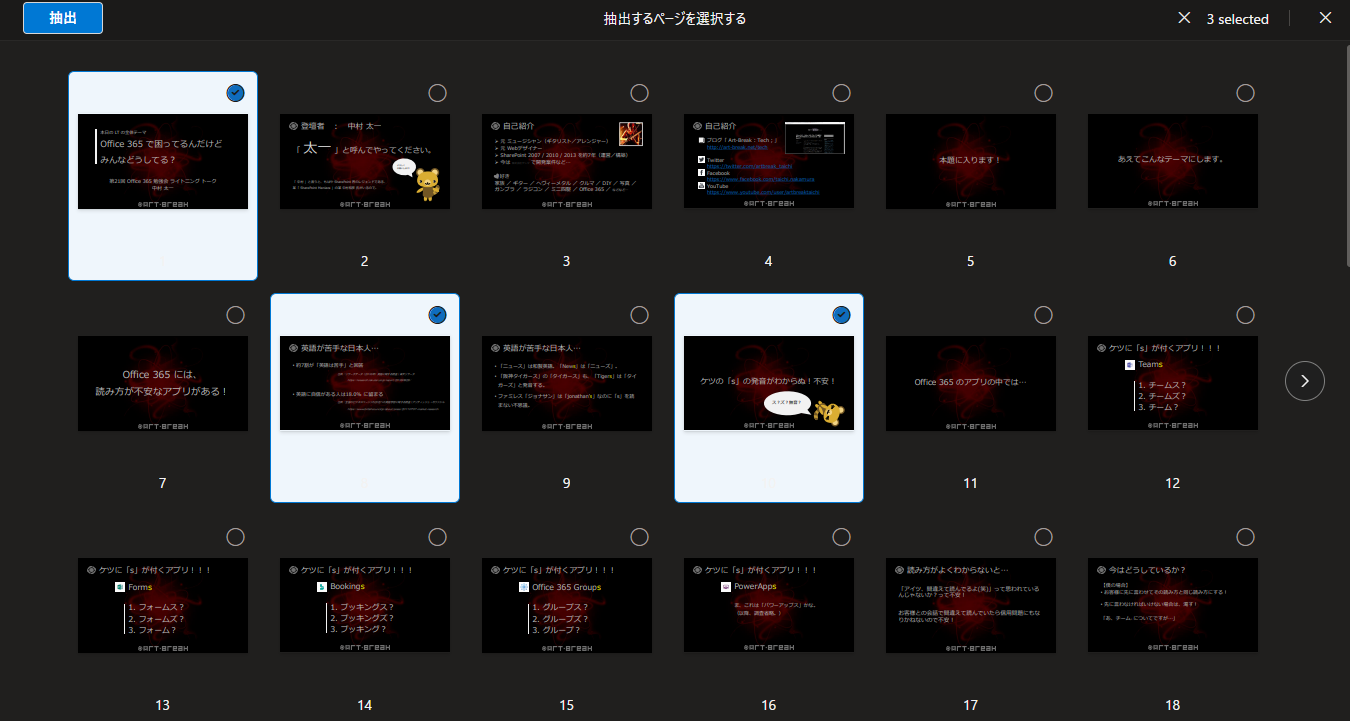
ここで抽出したいページを選択し、
▼左上の「抽出」ボタンをクリック
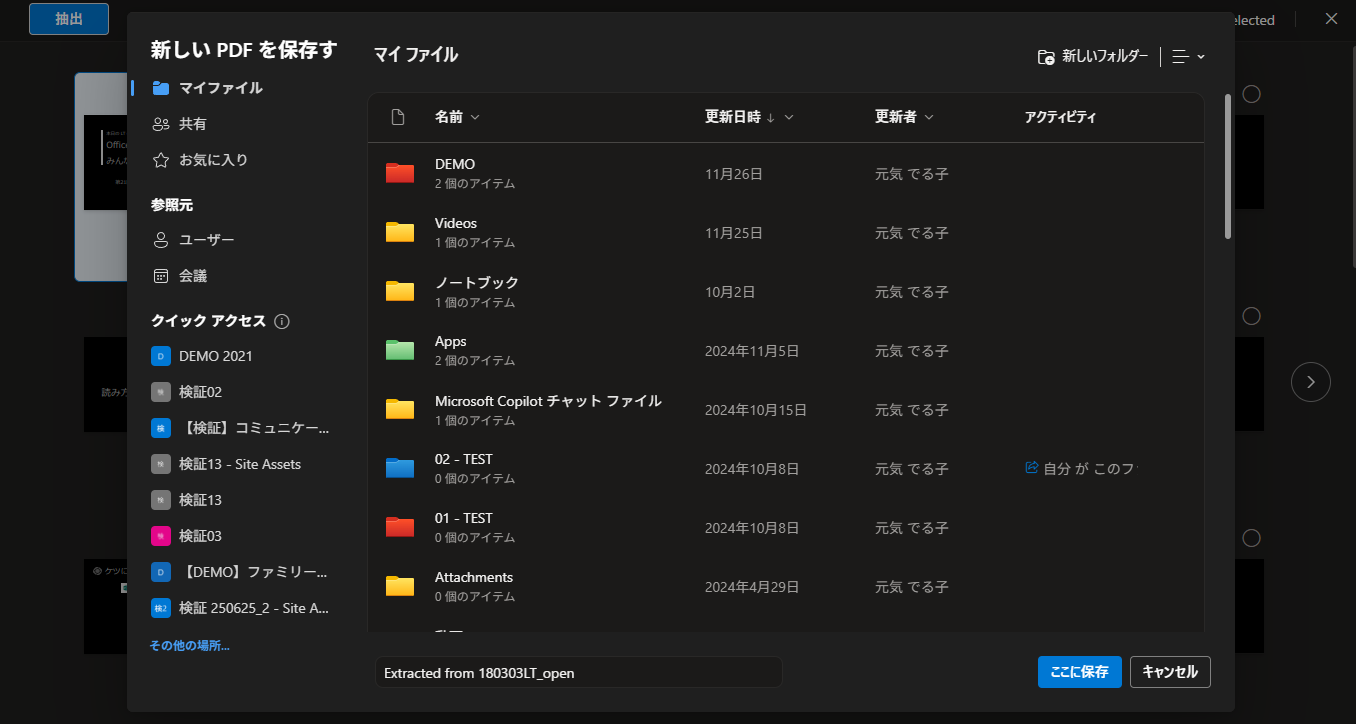
▼保存先を選択し「ここに保存」をクリック
良く見ると ODfB だけじゃなく SharePoint のライブラリにも保存できますね。クイックアクセスできるサイト。今回は元ファイルと同じフォルダー内に保存します。
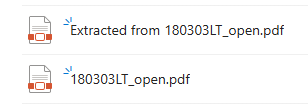
▼フォルダー内
このように抽出して作成した新規PDFファイルは「 Extracted from 」がオリジナルファイルのファイル名の前に付くファイル名で保存されていました。当然開けば抽出したページのみのPDFファイルになっていました。
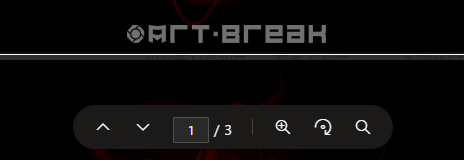
▼3ページ
元ファイルは52ページもあった中から3ページだけ抽出したので、しっかりと抽出して新規PDFファイルとして作成されていました。
これが Microsoft 365 から離れずともビューアーの中で操作が完結できるという点は素晴らしいですね。今後も残りの機能を試していきたいと思います。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}